
ClickLocker is marketed as a digital security solution that allows a content author to easily manage their digital rights by enabling them to regulate access to their ebook, video, or software product. While the ClickLocker website claims that "ClickLocker provides the industrial-strength security you deserve", this is a blatant exaggeration and misleading statement. When we think of industrial-strength security, we assume that this implies the use of cryptography. However, this is not the case with ClickLocker. In this tutorial, we will reverse engineer the ClickLocker Demo application to show you how easy it is to extract an embedded file without the need of a valid license code. To begin, let's download the demo application below.
http://www.clicklocker.com/ClickLockerDemo.exe
After you have finished downloading, let's scan the file with a protection scanner. In this example, I used ExeInfoPE.

As we can see, the target application is simply compressed with UPX. This is quite common with most clicklocker applications I have encountered. To remove this, we will simply use the UPX command line utility with the -d parameter to decompress the target.

Now that it is unpacked, we can begin debugging the application. However, before we start, I will give you a quick rundown of how ClickLocker works so that we can understand how the unpacking process works.

When you start a clicklocker protected application, it will ask you to enter a license code to unlock the program. Once you have entered the 8 digit key, it will connect to the clicklocker server and to verify the license code. Once it checks the license key, it will return 1 of 5 possible strings from the server. Those strings are "good", "bad", "new", "used", "expired", or "suspended". By looking at these, I am sure you can guess that the value we need returned by the server in order to unlock the program is "good". When we enter the key 12345678, chances are, that the server will return the value "bad". In order to exploit this, we will just need to change the returned value to "good". Once the license has been verified, the program will extract the file to the TEMP directory under a random name, apply a super hidden attribute, execute the file, and then delete it. Our goal is to arrive directly after it extracts the file to disk and before it applies the super hidden attribute. To begin, let's go ahead and open the application in Ollydbg and search for all referenced text strings.

First, let's set a breakpoint on all 4 references to the string "good". Afterwards, we need to search for the string "Authenticated Successfully!" This value is returned after the unlocking process is successful. Once you have the breakpoints set as in the picture above, let's start the program in ollydbg and enter the key "12345678".

After clicking Unlock Now, we will break on one of our "good" breakpoints.

Once we arrive here, we can see that both EAX points to the "bad" string returned from the server while ECX contains its size of 3. In order to trick the program into believing it was authenticated by the server, we need to change the string "bad" to "good" and the size in ECX to 4, which is the length of the new string. Let's follow the dword of EAX in the dump so that we can alter the string value.

Now, let's simply change the value to "good".

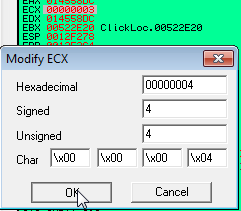
Once you are finished, we just need to change the value of ECX to 4 so that it is the same length as our new string.
Now, let's run the program. If everything was done correctly, we should arrive at the "Authenticated Successfully!" string 2 breakpoints later.
At this point, we simply need to press f8(step over) 8 times to arrive here:
At this point, follow the value of EDX, which was assigned by the instruction at 4DBF26 in the dump to get the path and name of the file that will be extracted.
Let's note this path and file name and press F8. After the called routine is finished, it will have extracted the protected file to the temp directory under the name we had above. Let's open our temp directory and find it.

As you can see, we have found our extracted file. If for some reason you are unable to see your file, it may already have a super hidden attribute which is often the case with PDF files. In that case you need to change your folder settings to show hidden files and uncheck the option which says hide protected operating system files.

After doing this, you should be able to find your file. If I recall correctly, a pdf file may have a .tmp extension in order to better hide it. Once you have found the file, you can simply move it to a new directory, rename it if you like, and use the command line parameter attrib -s -h filename.ext to remove the supper hidden attribute if needed.

Once you are finished, you have successfully beaten this protection. Let's run the application to verify:

Now that we are finished, I must state that the goal of this tutorial was NOT to teach you how to pirate a ClickLocker protected product, but rather to show you that this product is not as strong as their website implies. A good DRM management software would employ encryption that could not be broken without a valid decryption key being supplied by the server upon activation. This is far from the case with ClickLocker. While my goal here is not to defame ClickLocker, I hope that you will consider these factors before using their low security product. Until next time, happy reversing.
you really go in at the deep end m8...
ReplyDeleteif you just rip the appended data,its done
the appended file has some struct appended to it, 0x28 bytes (give or take), first dword is the file size, and some settings, and a version number / tag
so you could just write an 'extractor' for it, much easier than cracking it
seems the upx is only on their code too for their wrapper
so its.. wrapper -> upx -> append 'real' file to end of upx'ed file -> apply 0x28 bytes of the 'final struct'... done
I thought about the rip approach, but since this can be used to protect an array of different file types such as PDF, SWF, MP4, and much more, I thought this would be a little easier than trying to identify the many possible file types and ripping them manually. An extractor would be a good project for the future. I hope everything is well with you.
ReplyDeleteBest Regards,
Chester Fritz :)